10 prácticas técnicas en equipos Scrum, Kanban y XP
Uno de los temas más controvertidos en torno a marcos como SCRUM es el de las prácticas técnicas. En este artículo recorro el camino desde la ausencia total de prácticas técnicas hasta adquirir la capacidad de hacer Continuous Delivery (CD). No es un camino fácil, pero tampoco es opcional. Cualquier equipo o empresa que quiera construir un software excelente, debe plantearse seriamente implementar esas prácticas.
Una de los tópicos más repetidos cuando trabajo con clientes es: «No puedes esperar los beneficios de hacer las cosas fáciles (las ceremonias de Scrum) si no estás dispuesto a invertir en las difíciles (las prácticas técnicas)». Scrum evita deliberadamente recomendar prácticas técnicas, ya que estas deben ser dejadas a elección de los equipos. Un buen Scrum Master sabrá introducir una curiosidad en todas las que pongo a continuación.
1. Refactorización
Refactorizar es la A del alfabeto de un desarrollador. Supone escribir código que funcione y luego perfeccionarlo y modelarlo hasta que alcanza una cota de perfección aceptable, a la vez que fácil de leer y mantener por otro desarrollador. Así, intentar preparar de antemano la solución perfecta es muy difícil, aunque seas un programador brillante. Perfeccionar haciendo maravillas con el lenguaje supone que la persona que venga después a mantener el código lo va a pasar mal para entender lo que hace el código.
Una de las implicaciones de esta práctica es encontrar por un lado a desarrolladores que sean lo suficientemente humildes como para aceptar que su código puede ser refactorizado y empresas que tengan suficientemente claro que refactorizar no es un gasto sino una inversión de cara al futuro. Y por si a alguien le quedan dudas, sí, el 100% del código que escribimos puede ser mejorado de múltiples maneras.
Tres principios para grabarse a fuego trabajando en un equipo ágil que aspire a construir software de calidad: KISS, SOLID y DRY
2. Control de versiones y Branching
A pesar de tener varias décadas ya, hay algunas empresas que todavía no entienden los beneficios de un sistema de Control de Versiones. Incluso cuando uno trabaja solo, hacer commits frecuentes y tener una estrategia de branches para implementar cada feature hace mucho más sencillo que la construcción del software sea lo suficientemente sólida como para no tener que volver atrás cada poco tiempo, además de proporcionar un histórico muy necesario para saber donde lo has hecho mal.
Trabajando en un equipo esto no es que sea positivo, es que es totalmente necesario. Saber quien hizo que y que pasó cuando es, literalmente, ahorro de dinero cada hora. Y el que tenga dudas, es que nunca se ha tenido que sentar durante horas a intentar integrar el trabajo de sólo tres personas para ver que estaba fallando, dejando el código plagado de parches y ñapas.
Actualmente el sistema de control de versiones más popular es Git, siendo Github y Gitlab las forjas más populares para el mismo. Aprender a usarlo no lleva más de un par de horas y bien usado es una revolución para cualquier organización.
3. Métricas de calidad del código
Saber en cada momento como es la calidad del código que escribes es necesario cuando trabajas haciendo software empresarial. Mi opinión es que también lo es en una startup cochina.
En este caso no hablamos de lo que hace el código, sino de su estilo. Mantener un código ordenado, bien comentado, con funciones cuya complejidad ciclomática sea lo suficientemente pequeña como para que cualquier programador pueda comprenderla, con métodos bien aislados y que asegure que es fácil de mantener, es algo fundamental cuando el planteamiento es el de una carrera de fondo y no el de terminar el próximo sprint.
Aquí he visto de todo y en distintos sabores. Desde empresas que no permitían más de cuatro líneas por método y no más de 74 caracteres por línea hasta la que preferían métodos con una complejidad ciclomática de 30 porque ellos lo valían y «no vamos a cambiarlo todo ahora».
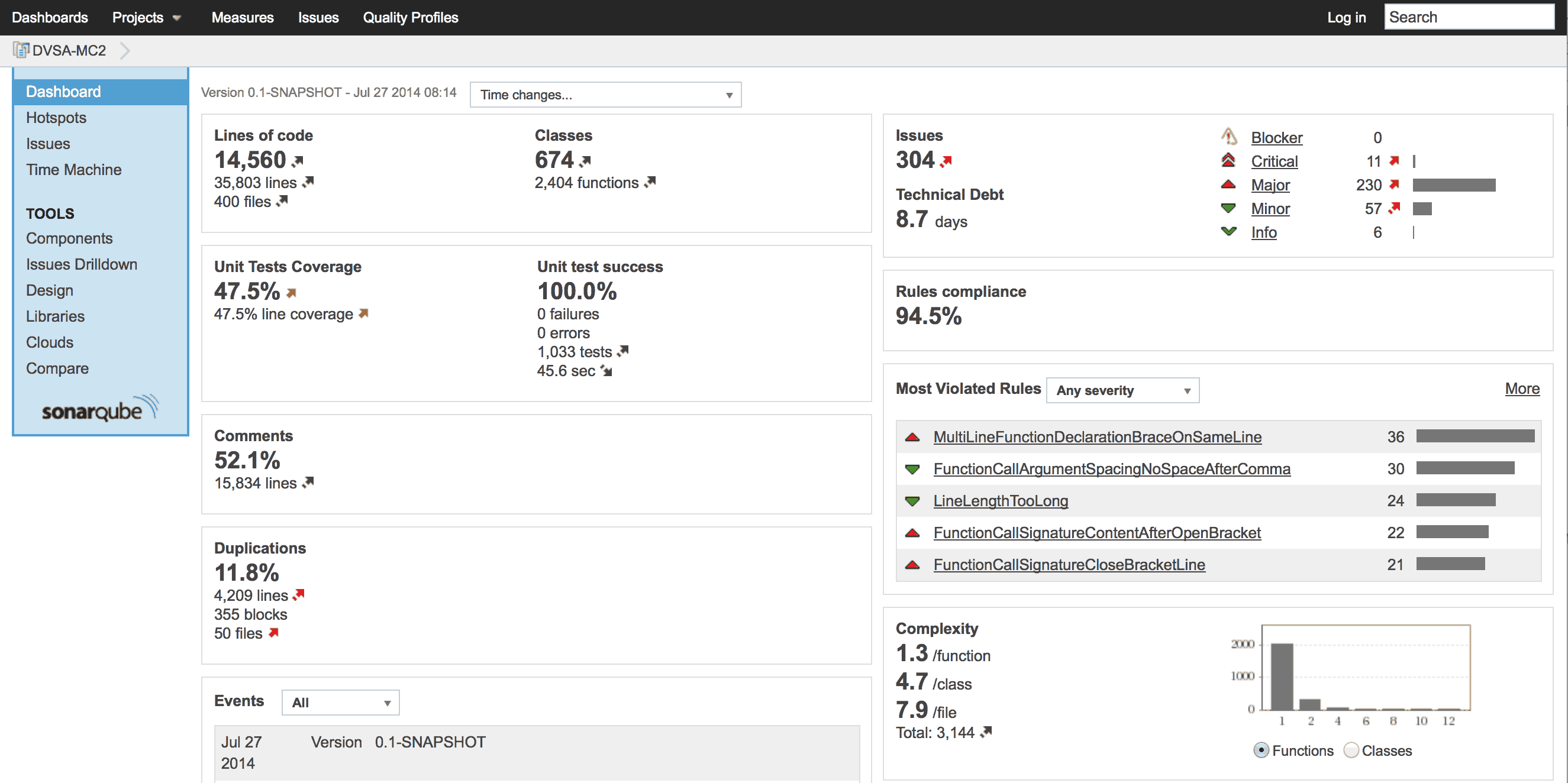
SonarQube es una herramienta que se encargará de analizar el código y decirte donde estás fallando, qué puedes mejorar y te dará una estimación de la deuda técnica en número de días. Una de las grandes ventajas de Sonar es que te permite analizar varios proyectos a la vez y darte unas visualizaciones muy bonitas del tamaño de cada proyecto, cobertura de tests unitarios, etc…
4. Test unitarios
El testing ha sido siempre objeto de controversia, pero en los últimos años hay ya pocas personas que aseguren que un código sin testear es un buen código (aunque algunas hay, que las han visto estos ojitos que se han de comer los gusanos). El objeto de hacer testing es triple: en primer lugar, asegurarse de que el código que escribimos efectivamente haga lo que dice que va a hacer. En segundo lugar, proporcionar un andamiaje consistente que hará que, en el futuro cuando refactoricemos el código, nuestro nuevo código sigue haciendo exactamente lo mismo que el antiguo y por último, que cuando estemos tocando una parte de la aplicación, no rompamos en otro sitio sin darnos cuenta.
A pesar de ello, podría decir que todavía encuentro un gran porcentaje de los proyectos que no tienen ni una línea de código referida a los tests. Las excusas son diversas, siendo la más divertida para mi que «hay que contratar testers para eso». Mi respuesta es, con distintas variaciones, la que sigue: «¿Cuando tu vas al baño, te limpias tu el culo o contratas a alguien para que lo haga?»
Quizás para hacer test de integración si pueda ser razonable tener a un especialista en automatización (ojo, creo que los programadores deberían ser responsables también de esto), pero los tests unitarios deben ser, sin duda alguna, responsabilidad de los programadores.
Sobre la cobertura de tests, el problema es el siguiente: puedes tener una alta cobertura pero unos tests malísimos (que testen varios métodos, por ejemplo) o unos pocos tests que den en el clavo. Como regla no escrita, parece que intentar conseguir una cobertura del 80% debe ser razonable.
5. Integración continua
Llegamos a una herramienta tan básica y que a la vez, muy pocos equipos (comparativamente hablando) han visto. Integración continua, un concepto tan desconocido como sorprendente. Es simple, si tu aplicación tiene una cobertura de tests suficiente, puedes tener un servidor que se encargue de detectar cualquier cambio en el control de versiones y encargarse de ejecutar todos los tests: unitarios, de servicios y de integración. Es como un mono que se encarga de asegurar que los cambios en el código no rompen la aplicación, porque la ejecuta de arriba a abajo (dependiendo de la cobertura de tests) cada vez que hay un cambio.
A pesar del más que evidente ahorro y capacidad de reacción ante cualquier pequeño cambio respecto de la aplicación, muchos equipos ágiles todavía no ven los beneficios de tener un servidor como Jenkins, Hudson, CruiseControl o Bamboo.
Muchas veces el problema no viene por no ver el evidente ahorro, sino por no querer abordar la evidente deuda técnica asociada a intentar poner en marcha este servidor de integración continua. Porque una cosa es instalarlo y otra cosa es usarlo correctamente. Para lo segundo, es necesario seguir como mínimo tres de los cuatro pasos anteriores, y eso supone una inversión en tiempo y en dinero que no muchos están dispuestos a asumir. Una triste realidad que te conduce inexorablemente a un momento donde tu producto será tan caótico que no habrá solución posible.
6. Test de la capa de servicios
Si estás utilizando una arquitectura N-tier en tu aplicación, que es una de las más habituales, lo más probable es que tu aplicación tenga una capa de servicios que actúe como API para el hacer de intermediario entre la persistencia de datos y la presentación u otras capas.
El problema de hacer testing unitario (métodos) y test de integración (presentación) es que puede ocurrir que algunos de los servicios dejen de funcionar correctamente y no seas capaz de detectarlo correctamente. El ejemplo puede ser un método que, a pesar de tener test unitarios, devuelve un valor aceptado por estos pero que hacen que otro método o función actúe de manera errática. Fitnesse es una tabla de decisión que prueba distintos inputs y espera diversos outputs en la capa de servicios, cubriendo el hueco existente entre los tests de integración y los tests unitarios.
7. Test de integración
Y llegamos al final de la santísima Trinidad del testing ágil: el testing de integración o de la capa de presentación. Existen muchos frameworks para automatizar este trabajo, y caso todos funcionan sobre Selenium. Es el caso de Behat, IntelliJ o Cucumber, por mencionar tres de los más famosos.
El testing de integración, que también puede (y debe) ser automatizado con un servidor de integración continua, asegura que la aplicación responde de la manera deseada en todos los casos. Sorprendentemente, hay muchas empresas que prefieren contratar a 10 o 12 personas para hacer testing manual de lo mismo, cuando podrían automatizar prácticamente el 80% de ese trabajo. No estoy en contra de los test exploratorios o manuales, estoy a favor de automatizar un trabajo que puede realizar una máquina en la mayoría de los casos y que puede proveer de un importante feedback al desarrollador en apenas unos minutos y no en horas, días o incluso semanas.
8. Test de regresión
Los test de regresión no son un tipo concreto de tests sino una suite que implementa test para probar cualquier bug crítico o importante que se haya detectado en la aplicación antes. Así, puede ser que en nuestro código haya un bug, que este sea detectado por una persona haciendo test de exploración y que se arregle pero no se vuelva a testear. Tenemos un cóctel perfecto para que, en poco tiempo ese bug, vuelva a reaparecer. Es por ello que en equipos ágiles se construye una suite de regresión que se ejecuta en el servidor de integración continua para agitar que fallos que sucedieron en el pasado vuelvan a suceder.
9. Continuous deployment
Nos acercamos al final y completamos el ciclo de Continuous Delivery con una de las prácticas más sencillas, siempre que se hayan seguido las anteriores: despliegue continuado. Una vez que el servidor de integración continua ha detectado un cambio en el master del control de versiones, ha ejecutado los test unitarios y pasan correctamente, ha hecho lo propio con los test de servicio y la presentación, lo único que nos queda es, ahora que sabemos que nuestro producto está correcto, poder desplegar de forma automatizada al servidor de preproducción y, tras ver que no hay ningún problema, cada dos o tres sprints y, siempre que haya nuevas features terminadas, desplegar a producción de forma automatizada.
10. Documentación
Por último, todo esto debe ir soportado por la documentación. Lo positivo es que actualizar la documentación no debe suponer más de 30 o 40 minutos con herramientas que te permiten elaborar una ayuda explorando el código, teniendo las releases notes extraídas de una herramienta como JIRA y utilizando los tests como base para explicarlas.
Conclusiones
A pesar del cada vez más creciente hype en torno a las metodologías ágiles, todavía hay mucha candidez en torno a las prácticas técnicas a usar en entornos ágiles. A pesar de que puede parecer una gran inversión en tiempo y en dinero, el retorno es muy alto cuando puedes permitirte hacer releases continuas cada dos semanas en lugar de cada tres meses, donde el 80% del tiempo se pasa en arreglar los problemas que el nuevo código ha provocado. Aquí es donde se pueden empezar a apreciar beneficios como la hiperproductividad del que muchos gurís hablan. Por último, empiezo igual que al principio. Lo fácil es hacer retrospectivas, daily stand-ups y planning meetings. Éstos pondrán en evidencia la necesidad de implementar algunas o todas estas prácticas, y mientras no se haga, es imposible esperar resultados distintos.