
Estimaciones conjuntas en SAFe
Idea inicial que plantea SAFe en la formación
Durante las formaciones de SAFe hay un momento en el cual los equipos deben calcular su capacidad para poderse planificar su carga durante la siguiente iteración.
En la simulación se considera que “Cada miembro del equipo de Desarrollo aporta 8 puntos al equipo por sprint de 2 semanas”. Esto resulta una sorpresa, negativa, para la gente habituada a trabajar con metodologías Agiles y utilizar la herramienta de las estimaciones relativas.
¿8 puntos por persona es poco? ¿o mucho?
Lo importante de este punto no es la cantidad de puntos que aporta cada miembro del equipo, sino una idea mucho más poderosa: las velocidades de los distintos equipos deben tener una referencia común.
El hecho de que todos los equipos que participan en la elaboración de una solución tengan velocidades comparables nos sirve para tener una predictibilidad de una manera sencilla. Ésta es la clave: predictibilidad poder saber si llegamos a la fecha comprometida o cuando habrá nuestro producto MMF (Minimum Marketable Features) estará listo para salir al mercado.
Cuando los equipos están empezando en la adopción Agile, esta propuesta de capacidad para el equipo es adoptada sin ningún problema. Pero ¿qué pasa con los equipos que ya tienen su propia definición de capacidad? ¿Qué sucede con la predictibilidad cuando necesitamos conocer las estimaciones de muchos elementos donde participan varios equipos en su elaboración? Y donde cada uno tienen sus criterios tanto de capacidad como de estimación relativa definidos.
Entender la adopción de SAFe
Aunque pueda ser presentado como un marco de trabajo, SAFe no es exactamente eso. SAFe es una base de conocimiento probado e integrado para el escalado de las prácticas Agile en las empresas. Me gusta presentar SAFe, sobre todo, como una biblioteca de herramientas para escalar la agilidad.
El símil de la biblioteca es muy válido, pues si no tenemos asimilada la mentalidad Agile el uso que le demos a las herramientas quizás no sea el mejor ni nos aporte ningún beneficio. Es como ir a una biblioteca de Francia sin saber francés, no podremos obtener todo el beneficio de aprender todo lo que los libros en francés nos quieren transmitir.
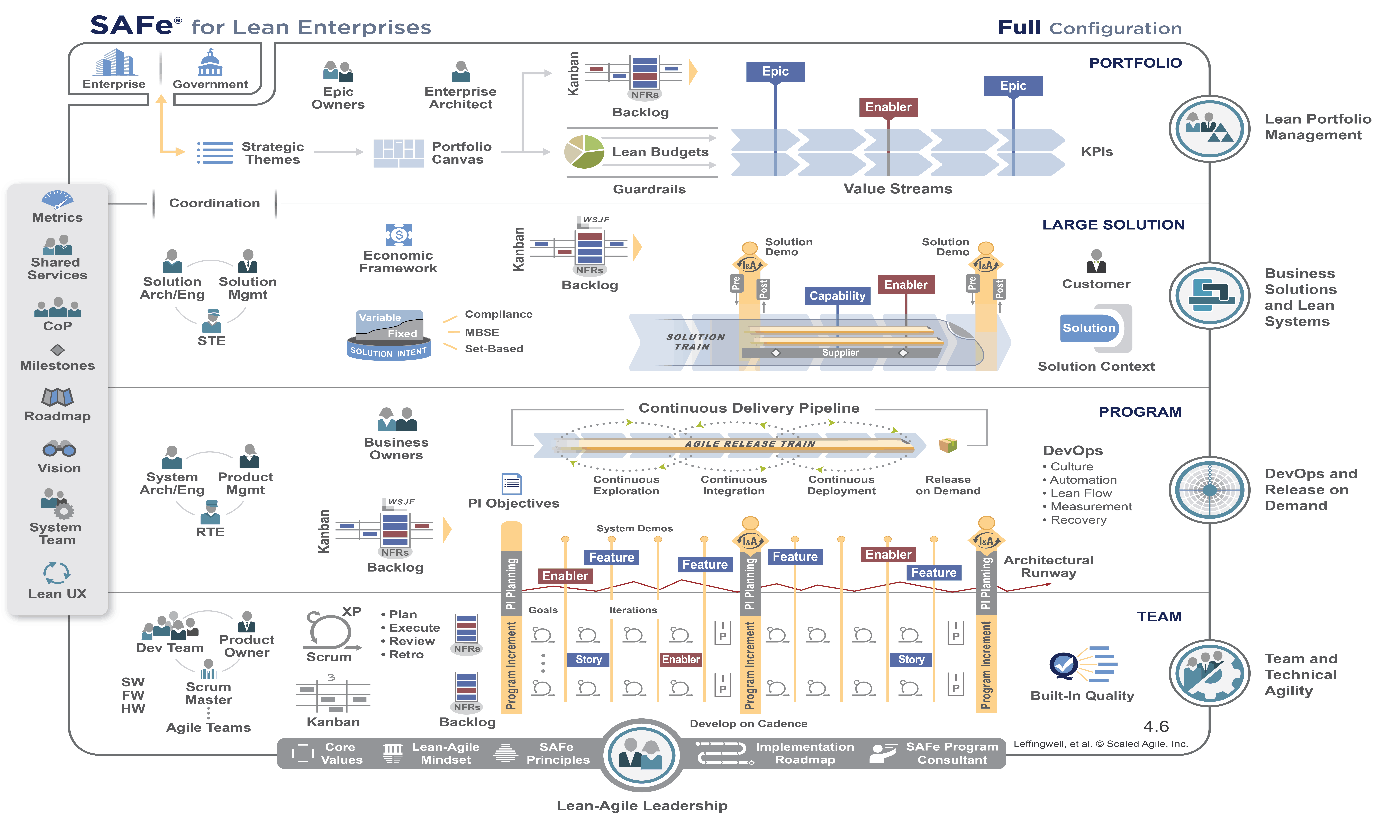
Las estimaciones relativas son una herramienta más de esta biblioteca, para equipos con poca experiencia en las metodologías ágiles, la propuesta de SAFe es aceptada como válida.
¿Y qué sucede con equipos más experimentados?
En una ocasión nos encontramos con que la empresa tenia ya una cultura Agile y existían varios equipos ya trabajando cada uno en sus productos que luego se integraban en la solución final.
Cada equipo hacía un producto, y algunos productos los podían hacer entre varios equipos. Las velocidades y estimaciones eran totalmente independientes entre ellos: había equipos que completaban 400 SP (story points o puntos de historia) en un sprint de 2 semanas y otros que hacían 20 SP. Los había cuya capacidad era 100sp, 150, 80, etc.. cada equipo había definido su manera de estimar y esto era perfecto a nivel de equipo. Y no era más eficiente el equipo de velocidad 80 que el de 20, ni que el de 400, era un tema de distintos criterios de valoración.
El reto se planteaba cuando necesitábamos saber si llegábamos a tiempo para entregar el proyecto incluyendo a todos productos. Poder estimar con cierta fiabilidad requería:
- Descomponer las épicas de programa para identificar los productos relacionados
- Cada equipo indagaba sobre las historias de usuario que les afectaba de la épica
- Se estimaban todas las historias de usuario.
- La estimación por equipo de las historias se agrupaba de manera que teníamos la estimación total de la épica para ese equipo
- Las estimaciones parciales de las épicas se agregaban para obtener una estimación a nivel programa.
¿Qué sucede si cada equipo tiene su propio criterio?
Como cada equipo tenia su propio criterio se nos plantean varios retos:
- Necesidad de saber exactamente quien hará cada épica. Había épicas que las podría hacer cualquier equipo y era muy poco flexible definir el responsable al inicio del proyecto. ¿y si luego ese equipo no la implementa? Esto era un gasto de tiempo en la estimación inicial que no servía.
- Necesidad de ponderar cada una de las estimaciones para cada equipo para poder tener una velocidad combinada que nos permitiera tener predictibilidad. El esfuerzo era grande y resultaba que un equipo en un momento dado decidía cambiar sus referencias y las estimaciones ya no eran válidas, y se tenía que recalcular todas las estimaciones donde participaba ese equipo.
- La cantidad de tiempo dedicado a las tareas anteriores era muy elevada.
Esta era la situación a la que nos enfrentábamos, necesitábamos tener predictibilidad a un coste inferior.
Se les planteó a los equipos nuestra necesidad y se decidió crear una Task Force con miembros de todos los equipos para definir un criterio de estimación común.
Primera iteración: Definir 1 SP para el tren
Los equipos en SAFe se agrupan por trenes, un tren es un equipo de los equipos que trabajan para un mismo programa. Lo lógico parecía que era probar esta idea en un tren antes de extenderla a toda la organización.
De esta manera nos fuimos reuniendo semanalmente 2 horas para compartir visiones de lo que suponía 1 Story Point para cada equipo.
Finalmente, conseguimos establecer un criterio común para todos de unas historias de usuario tipo que representaban la complejidad de 1SP.
Nos llevó nuestro tiempo, pero ya teníamos una referencia.
Segunda iteración: Definir algunos valores más de referencia (2SP, 5SP y 10SP)
Una vez teníamos definida las características de la Historia de Usuario tipo para todos los equipos del tren, el siguiente reto era definir alguna otra historia de usuario referencia mayor que 1 SP.
Los equipos empezaron a trabajar en la Historia de Usuario tipo para 2sp y empezaron otra vez las dificultades para alcanzar un acuerdo y la cosa se complicó más cuando trataron de definir una historia de 5 sp. En ese momento, la propuesta pasó a ser redefinir la historia de usuario inicial de 1 sp… Volvíamos a estar en el mismo punto que 2 meses antes.
Era momento de pivotar y buscar otro tipo de soluciones.
Tercera iteración: introducción de #NoEstimates
El siguiente experimento era probar de adoptar la idea de #NoEstimates, ya que usaba un elemento de referencia común e indiscutible para todos los equipos: la duración del sprint.
La idea de #NoEstimates se basa en el hecho de que, para tener predictibilidad en la consecución de un objetivo de negocio, no es necesario dedicar una cantidad ingente de tiempo a estimar todos y cada uno de los elementos.
#NoEstimates propone tener como referencia una duración, y que la “estimación” sea comparada sobre si es menor o mayor que el tamaño referencia.
Escogimos como referencia medio sprint, es decir 1 semana. Los equipos solo necesitaban analizar si la historia de usuario se podía hacer en una semana o menos. En caso afirmativo, pasaban al siguiente elemento. En caso negativo, se descomponía el elemento en otros más pequeños y nos repetíamos la pregunta sobre si cabía en medio sprint.
La predictibilidad se obtendría del numero de elementos que se finalizaban por equipo durante un sprint.
De esta manera obtuvimos beneficios casi inmediatos:
- Los equipos dedicaban menos tiempo al proceso de estimación.
- Los equipos estaban motivados a estimar, ya no era una tarea tediosa.
- No hacía falta ponderar las velocidades pues contábamos elementos finalizados.
- No era necesaria saber de antemano que equipo haría que épica pues al final la diferencia en el desarrollo de los equipos no era significativa.
- Cambió el ambiente hacía una colaboración mayor entre equipos
No podía existir falta de acuerdo entre los equipos pues medio sprint era lo mismo para todos.
Cuarta iteración: #NoEstimates a nivel de programa
Viendo el éxito de la adopción de esta práctica a nivel de equipo, nos planteamos los beneficios de escalarla a nivel de programa. Sonaba razonable, si al cliente le entregamos épicas pues porque no estimar directamente a este nivel.
El resultado fue muy satisfactorio, ahora miembros de los diferentes equipos del tren (Dev team y Product Owners) estimaban si las épicas podían hacerse en la mitad de una iteración de PI (program increment o Incremento de Programa). Es decir, la referencia para las épicas era si podían completarse en 6 semanas de trabajo (1 PI = 6 sprints, 1 sprint = 2 semanas).
Llevó un tiempo acostumbrarse a esta nueva escala de comparación, y aun así funcionó muy bien. Los equipos ya no necesitaban dedicar tanto tiempo a estimar, descomponer detalladamente las historias de usuario, sino que había una estimación a más alto nivel.
Como es normal, a este nivel la desviación podría ser mayor, pero al ser el margen (6 semanas) también muy grande quedaba bastante compensado. No hubo apenas épicas con grandes desviaciones de las estimaciones iniciales.
Take aways
De esta experiencia nos podemos llevar varios puntos interesantes:
- Nueva herramienta para estimar: #NoEstimates
- Idea clave sobre el aprendizaje: Aprender es un proceso iterativo experimental.
- Lo importante no son las herramientas, sino el propósito que buscamos alcanzar con ellas.