
Ciencia de Datos, Producto y Agilidad
Muchas son las empresas que se están amparando en la agilidad para sobrevivir ante un mercado y contexto social cada vez más dinámico y donde la disrupción de tecnologías, nuevos modelos de negocio y gestión del talento han hecho que antiguas mentalidades y formas de trabajo no sean las más adecuadas para estos tiempos.
La agilidad nos lleva a trabajar colaborativamente con equipos multidisciplinares y esto no excluye a disciplinas como la ciencia de datos, que además entendemos estratégica a todos los niveles de una organización. Cada vez son más las empresas que apuestan por obtener valor de sus activos en forma de datos, utilizando el talento de los científicos de datos para impactar considerablemente en el negocio.
Sin embargo, la (relativa) novedad de la ciencia de datos y la cada vez más habitual aplicación de las metodologías ágiles no siempre tienen una convivencia fácil en el contexto de creación de productos.
El objetivo de este artículo es buscar un punto de encuentro entre responsables de producto y los equipos involucrados en la creación de producto, asumiendo que la involucración de la disciplina de datos cada vez va a ser más habitual.
Nos gustaría Identificar y explicar los momentos donde esta disciplina es un factor diferencial en la creación de productos y cómo se podría organizar de forma ágil.
Cada responsable de producto tiene su propia manera de crear productos, basada normalmente en frameworks, métodos, gurús o experiencia (Lean Startup, Design Thinking, Scrum, SAFe, Less, etc) o una combinación de todo lo anterior.
Para evitar que nuestra conversación se focalice en frameworks o métodos, vamos a suponer que independientemente del framework que utilice, un equipo involucrado en la creación de un producto pasaría por ciertos “planos”, que representamos en la siguiente figura.
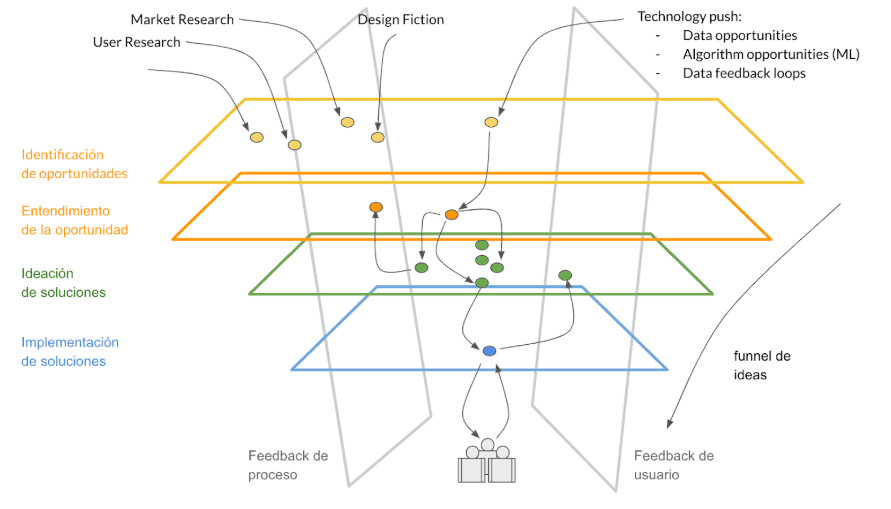
- Identificación de oportunidades: Registro de oportunidades que pueden venir de cualquier miembro o grupo de trabajo de la empresa.
- Entendimiento de la oportunidad: Entendemos el problema a solucionar o la necesidad a cubrir junto con el potencial impacto de negocio.
- Ideación de soluciones: Identificamos las posibles soluciones para solventar los problemas y las necesidades.
- Implementación de soluciones: Desarrollamos y entregamos los incrementos de producto a nuestros beneficiarios.
- Feedback contínuo: Comúnmente hablamos de feedback en relación al impacto y el valor esperado de la solución pero podemos pensar en el feedback como planos transversales a los anteriores, unos más orientados a la forma de trabajo y otros relativos al valor entregado.
Supuestamente a medida que avanzamos desde ideación hasta feedback, vamos disminuyendo nuestro nivel de incertidumbre (de ahí la forma de funnel). Además, la madurez del producto con respecto a su ciclo de vida influye a la hora de organizar el trabajo de creación de dicho producto.
A continuación vamos a recorrer cada plano explicándolo con más detalle:
Plano Identificación de Oportunidades
Asumimos que este plano representa el espacio donde todas las ideas u oportunidades son merecedoras de consideración. Dichas oportunidades pueden haberse originado en workshops de ideación, discovery, design thinking, resultados de una investigación con usuarios, estudios de mercado, análisis de la competencia, ideas de cualquier grupo de trabajo o miembro de un equipo que participe en la creación del producto, refinamientos, revisiones, etc.
Todas estas potenciales oportunidades de mejora o evolución del producto son recogidas de forma que puedan pasar a otros planos, normalmente a lo que llamamos Entendimiento donde articulamos dichas oportunidades (lo explicamos en el siguiente apartado)
En esta fase, el papel de la disciplina de datos y en particular la del científico de datos no se diferencia de la de otros roles, excepto porque las ideas podrían venir de un proceso relativo a la ciencia de datos, como por ejemplo el uso de nuevas fuentes de datos externas o internas, los avances técnicos en algoritmos o la identificación de ciclos de adquisición y realimentación de datos.
Uso de nuevas fuentes de datos (externas o internas)
En muchos productos uno de los diferenciadores puede ser el uso de datos. En este sentido identificar fuentes de datos diferenciales y poder valorar su utilidad en etapas tempranas del proyecto es clave para la viabilidad de las ideas generadas. Por ejemplo, podemos tener la idea de que la información en portales públicos de compra venta de pisos podría ser utilizada para mejorar la valoración del precio de una vivienda, que hasta ahora era generada basada en datos internos.
Avances técnicos en algoritmos
Algo similar ocurre con la disponibilidad de nuevas herramientas o algoritmos para el tratamiento de datos. En ocasiones, el acceso a un nuevo algoritmo puede hacer viable, técnica o económicamente, una idea. Los avances en algoritmos de Deep Learning aplicados a Visión Artificial han permitido rebajar el número de ejemplos necesarios para clasificar imágenes abriendo la puerta a nuevas aplicaciones. Por ejemplo, gracias a estos avances decidir si una imagen proporcionada contiene un coche es ahora mucho más sencillo y preciso.
Identificación de ciclos de adquisición y realimentación de datos
Otra tipo de aportación desde el equipo de datos consiste en identificar cuáles serían los mecanismos para obtener los datos deseables para nuestro producto y definir una estrategia para su adquisición. Esta estrategia, que DJ Patil define como Data Jiujitsu, ha sido ampliamente utilizada en el caso de las redes sociales como LinkedIn o Facebook para soportar su modelo de negocio.
Cabe destacar que el feedback de los resultados generados en otros planos (Entendimiento, Ideación, Ejecución, etc. explicado en apartados posteriores) podría ser una de las fuentes más interesantes de las que se puede nutrir el plano de Identificación.
Plano Entendimiento
En este plano articulamos la oportunidad y, por lo tanto, la hipótesis que tenemos con respecto al beneficio que nos reportaría llevarla a cabo, tanto a nivel de negocio como para nuestros clientes o usuarios. Además, en este plano podemos empezar a perfilar una visión o a alinearnos con una ya existente.
Como parte de ese refinamiento, el equipo de datos puede acometer tareas como:
Análisis exploratorio de datos para validar idea
Como parte del entendimiento de una idea, el análisis de los datos del mercado nos va a ayudar a definir mejor la oportunidad (público objetivo, segmentación, modelo de negocio, etc) y a acotar el trabajo a realizar en el resto de planos.
Identificar problemas e implicaciones éticas en el uso de datos
En esta etapa es necesario profundizar en las implicaciones de usar las fuentes de datos que se hayan identificado y la forma en la que se van a usar. En este caso hay que tener en cuenta tanto aspectos legales, de privacidad y éticos. Es el momento de identificar posibles sesgos en los datos y considerar si el producto agravaría esos sesgos.
También si es capaz de satisfacer a todos los usuarios objetivo, o por el contrario se requieren mecanismos o acciones especiales para que la solución elegida sea inclusiva. Por ejemplo, en aplicaciones que incluyen reconocimiento de voz se ha encontrado que la baja representación de ejemplos femeninos o de voces no nativas suele implicar un peor calidad en el reconocimiento para estos colectivos.
Viabilidad y análisis crítico de los datos disponibles
Es labor del equipo de datos, además del uso responsable de los mismos, velar por la utilidad práctica de dichos datos y así como de los correspondientes algoritmos. Aunque en la etapa de ideación es necesario mantener una mentalidad abierta para identificar datos que supongan una ventaja competitiva, en esta etapa es el momento de mirar los datos desde un punto de vista más crítico. Los sesgos en la recolección de datos, además de tener implicaciones éticas, pueden invalidar o limitar su utilidad en términos analíticos. Otro problema frecuente es que no se disponga de la profundidad histórica necesaria o no se recojan los datos con la frecuencia o la resolución necesaria.
Por ejemplo, un dataset puede registrar la fecha en la que sucede un evento pero en cambio, para ser útil en un nuevo contexto se requiere el timestamp con información de hora, minuto y segundo. Identificar este tipo de necesidades y problemas, así como corregirlos para que se disponga del histórico necesario también es responsabilidad de la disciplina de datos.
Plano Ideación de Soluciones
Este es el nivel donde pensamos en las diferentes soluciones para la creación del producto, así como todo lo necesario como para poder empezar a experimentar y aprender con algo tangible (a algunos les sonará el concepto de MVP).
El objetivo es definir las características del producto y en el caso específico de que requieran funcionalidades basadas en el uso y explotación de datos, abordar cómo se podrían construir.
A grandes rasgos las aportaciones que se pueden hacer desde el equipo de datos para contribuir a la solución se agrupan en los siguientes grandes bloques:
- Análisis Exploratorio de Datos: Se trata en este caso de responder preguntas de negocio, por ejemplo, mediante los datos de uso del producto. Estos análisis pueden ayudar a definir una estrategia de producto, escoger una solución o priorizar el problema en el que enfocarse.
- Visualización y Resumen de Datos: Muchos productos basados en datos incluyen alguna forma de visualización de los propios datos generados por sus usuarios, por ejemplo un gadget destinado a medir nuestra actividad física Es labor del equipo de datos buscar una visualización eficaz y adecuada.
- Predicción Es la capacidad para inferir el valor de una o varias variables de interés para nuestra aplicación Puede tratarse, entre otras, de la categoría de un objeto (imagen), el valor numérico de una cantidad medible (el precio de un vuelo) o las películas en las que puede estar interesado un usuario, como en el caso de un recomendador.
- Diseño de ciclos de realimentación de datos: Cualquier funcionalidad basada en datos tiende a obtener mejores resultados si dispone de más datos, así que parte de la labor del equipo de datos es definir mecanismos que permitan recogerlos y transformarlos en mejores predicciones o visualizaciones de mayor exactitud.
- Otras funcionalidades: La disciplina de datos puede proporcionar otras soluciones basadas en datos como la optimización o la simulación, ambas relacionadas con los puntos anteriores.
Como ejemplo, pensemos en una funcionalidad familiar para muchos de nosotros: organizar las fotografías de nuestro dispositivo móvil según las personas que aparecen.Si tratamos de asociar las aportaciones al diseño que puede aportar un científico de datos:
- En primer lugar, puede ser necesario clasificar qué fotografías tienen personas y cuáles no, que claramente es un problema de predicción.
- Del mismo modo, agrupar qué fotografías son de la misma persona aunque puede ser abordado de diferentes formas como clustering, clasificación o ranking, es en general, otro ejemplo de problema de predicción.
- Un tercer punto es cómo mostrar los grupos de fotografías que se podría clasificar como un problema de visualización de datos. Si bien podemos usar heurísticos sencillos (primero los grupos más numerosos o los que tienen alguna foto más reciente), también podríamos pensar en otros más complejos (primero las personas que aparecen en más selfies) que a su vez podría requerir más problemas de predicción.
- Además, podríamos facilitar que los usuarios pudiesen hacer sus propios grupos o quitar, poner o mover una foto mal clasificada. Si capturamos este tipo de acciones, podríamos usarlas para mejorar los modelos de predicción anteriores, que serían un buen ejemplo de la creación de un ciclo de realimentación de datos.
Para cada funcionalidad donde la ciencia de datos contribuye, hay que considerar la participación del resto de disciplinas (UX, visual design, backend, frontend, servicios, etc) y pensar en ¿qué impacto tiene para nuestros beneficiarios y/o negocio el hecho de ofrecer dicha funcionalidad? En este caso, podemos expresarlo como hipótesis de beneficio.
Por ejemplo, si incluimos la funcionalidad de ver fotos organizadas por personas, aumentará un 20% el tiempo que pasan los usuarios en la aplicación y crecerán los usuarios que suscriban un plan superior partiendo del journey “ver sus fotos organizadas”. Como consecuencia de esta funcionalidad esperamos aumenta nuestro beneficios un 5%. Es en este caso, el que el equipo de científicos de datos también puede colaborar definiendo los KPIs de negocio, definiendo el experimento científico y facilitando la obtención de conclusiones. Del mismo modo, mediante por ejemplo la realización de test A/B, podemos validar los resultados obtenidos con la entrega de un incremento de producto.
Plano Implementación
Este es el plano donde generamos un incremento de producto de forma que entregamos valor al cliente o beneficiario. Aquí el científico de datos tiene la oportunidad de contribuir en el impacto esperado con dicho incremento, “exprimiendo” lo trabajado en todos los planos anteriores y de forma conjunta con el resto del equipo, para así entregarlo a los correspondientes beneficiarios o clientes finales.
Se asume que gran parte del trabajo en entendimiento del negocio y en la decisión del enfoque análitico se ha llevado a cabo en los planos etapas previas de entendimiento e ideación. Para la disciplina de datos este plano abarca desde el trabajo técnico de la ingesta de datos, la validación de estos mismos, exploración, construcción del modelo predictivo (o de una visualización) hasta la posterior validación de sus resultados y en el mejor de los casos el despliegue de la funcionalidad y la infraestructura adecuada. Dejamos aparte la medición de los resultados del proyecto, y por tanto la obtención de feedback, como parte los niveles transversales.
Construcción interaccionando con otras disciplinas
Muchas veces existen complicaciones al compatibilizar el ciclo de desarrollo tradicional de la disciplina de datos con las iteraciones llevadas a cabo por el resto del equipo. Suponemos que el equipo en su conjunto es capaz de entregar un incremento de producto por ellos mismos, pero las dependencias y la burocracia son típicas complicaciones que entorpecen el flujo de valor. De hecho, son habituales no sólo para científicos de datos si no para cualquier equipo ágil en general. En muchos casos la solución está más relacionada con la organización y estilos de liderazgo. Aunque esta es una discusión muy interesante, no la abordamos directamente aunque sí podemos comentar una serie de comportamientos que obstaculizan la inclusión de un científico de datos en un equipo ágil. Se trata del mismo concepto pero abordado desde dos perspectivas diferentes, una desde el responsable de producto y la otra desde el científico de datos:
- El responsable de producto piensa que todos los miembros del equipo tienen que contribuir en cada iteración con un incremento de funcionalidad y no tanto en un incremento de valor, no entendiendo que la ciencia de datos conlleva cierta parte de experimentación (incluso investigación) con niveles bajos de predictibilidad: Esta preocupación se hace más latente cuando un equipo no trabaja de manera multidisciplinar y colaborativamente para conseguir un objetivo, sino que se distribuyen el trabajo por disciplina o tecnología. La peor consecuencia de esta forma de trabajo es la imposibilidad de entregar valor con un flujo continuo, haciendo necesaria la integración (en algún punto futuro) de las diferentes partes implementadas a lo largo de los anteriores sprints, creando un estilo de trabajo waterfall. Por lo tanto, es importante entender que el científico de datos podría tener como resultado final de una iteración, un aprendizaje o algo que no se incluya directamente en el incremento de producto. Pero son estos experimentos los que nos llevan iterativamente a conseguir algo que finalmente sí contribuya en el incremento de producto (normalmente de manera muy significativa).
- El científico de datos trabaja en una caja negra que se integra con el resto de funcionalidad cuando tiene un rendimiento determinado: Entendemos que las iteraciones deberían de ser incrementales, pero del producto y no solo de la parte de datos. Hay que entender que es el equipo el que tiene como objetivo entregar un incremento de producto que aporte valor en cada iteración, y no partes específicas del equipo o individuos concretos. Como consecuencia, los ciclos de inspección y adaptación son del producto, donde el valor aportado por un incremento depende de todas las disciplinas aunque alguna sea más estratégica que otras. Por ejemplo, por muy brillante que sea un algoritmo, no va a tener el impacto esperado si UX o el visual designer no lo hace deseable o usable para el usuario, o de igual forma, las personas de operaciones no han conseguido la disponibilidad que el usuario espera.
Cadencia, Timebox, Avance Iterativo e Incremental
Creemos que merece la pena comentar un tema bastante habitual cuando científicos de datos pertenecen a un equipo ágil que itera con un timebox típico de por ejemplo 2 semanas.
Al final de la iteración se espera un incremento de valor, este incremento puede tener diferente naturaleza, aunque al final muchos entiendan o simplifiquen este valor a beneficio financiero, que ya sea de forma directa o indirecta.
La naturaleza del valor aportado en esta fase puede tener un potencial de predictibilidad diferente, de forma que ciertos trabajos sean más de research con un nivel de predictibilidad bajo y otros más de ejecución con alto nivel de predictibilidad. Normalmente está relacionado con los planos explicados con anterioridad, donde por ejemplo la predicción es complicada si nos encontramos con actividades del nivel de identificación de oportunidades o entendimento.
Cuando tenemos objetivos complicados de estimar debido a que el camino para conseguirlos es difuso, las prácticas iterativas destinadas a conseguir un objetivo en un timebox determinado podrían no ser demasiado útiles. De esta forma, intentar meter todo el trabajo realizado por los equipos en todos los planos dentro de la iteración de dos semanas, no tiene sentido en muchas ocasiones. Pero eso no quiere decir que los ciclos de inspección y adaptación no sean útiles en cualquiera de los planos, en nuestra opinión siguen siendo útiles para gestionar las expectativas del propio equipo y de los diferentes stakeholders. Sería el plano de implementación donde las iteraciones con un timebox específico resultarían más adecuadas.
Aun así, la labor de construir una funcionalidad completa basada en datos en el nivel de implementación, en un periodo de dos semanas es en general complicada. Es la labor de los responsables de producto y los científicos de datos establecer la estrategia adecuada para facilitar la entrega de incremento de producto en el menor tiempo posible sin que eso implique tener una funcionalidad completa.
Estas son algunas estrategias para facilitar el trabajo colaborativo de un DS con el resto del equipo:
- Construir hacia atrás. En ocasiones disponemos de funcionalidades que se pueden empezar a desplegar mediante heurísticos sencillos que luego podemos reemplazar con algoritmos más complejos. En este caso podemos trabajar en integrar estos heurísticos como un stub con el resto de la aplicación y junto al resto del equipo. La gran ventaja es que podemos empezar a testear el valor que la funcionalidad aportaría al producto sin necesidad de construir una funcionalidad completa.
- Construir por dominios de datos. En este caso el objetivo es identificar cual es el conjunto mínimo de datos que facilitan la mejor aproximación al modelo ideal. El objetivo es centrarse solo en la adquisición de estas fuentes de datos y su explotación combinando criterios de utilidad y disponibilidad. Posteriormente se pueden ir incrementando el número de dominios de datos a introducir.
- Construir por incremento de resolución. Uno de los grandes problemas en el tratamiento de datos es que tanto la adquisición y limpieza de datos requieren una gran cantidad de tiempo. En muchos casos, es viable rebajar los requisitos de este procesos si en vez de un incremento de producto, buscamos un incremento de valor. Como por ejemplo determinar si una fuente de datos o un enfoque es el adecuado.
- Construir mediante incrementos de complejidad. En general, conviene explorar el uso de los algoritmos (o visualizaciones) más sencillos o estándar antes de buscar soluciones más complejas, y que requieren mucho más trabajo y experimentación. Hay pocas cosas peores que contrastar, gracias al feedback de los usuarios que la funcionalidad que hemos tratado de resolver, no es en realidad deseable. Es preferible determinar cuánto antes que se trata de una funcionalidad interesante aunque requiera de mayor exactitud o sofisticación para ser útil.
Planos Feedback
Representamos el feedback como planos que cortan de manera transversal al resto de los planos. Un tipo feedback serían el relativo al proceso o mejora de la forma en que se trabaja para crear el producto en cada uno de los planos. El otro tipo de feedback se corresponde con la forma con la que que podemos validar nuestras hipótesis y criterios de éxito para pivotar o persistir en nuestras siguientes iteraciones. El feedback puede tener lugar dentro de cada plano debido a que una iteración no implica necesariamente un cambio de plano.
También puede tomar varias formas, desde el feedback cualitativo del equipo o de los usuarios hasta feedback cuantitativo. Precisamente es en este último, donde la disciplina de datos también ha contribuido en el diseño de experimentos destinados a la validación de hipótesis del producto, de la solución o sobre detalles de la implementación. Cualquier cambio o mejora, como un nuevo algoritmo para una predicción o un cambio en la interfaz, es susceptible de ser validado con usuarios reales.
Uno de los mayores retos es que el periodo para obtener feedback accionable es demasiado largo como para trabajar en iteraciones cortas. Para afrontar esta problemática podríamos definir leading indicators que nos permitan validar nuestras hipótesis a más corto plazos.
Ejemplos de Implantación
Dependiendo del contexto la forma de aterrizar todo lo explicado en los anteriores apartados puede variar considerablemente. Especificar un framework para todos los casos sería una simplificación de una situación que seguramente es muy compleja. Incluso algunas personas pensarán que para todos o la mayoría de casos, la utilización de un framework es un error y la mejor aproximación sería la mejora contínua de los equipos basada en principios y valores ágiles sin especificar prácticas específicas.
Con la simple intención de ayudar a generar ideas, algunas alternativas serían:
- Realizar el trabajo con sistemas Kanban de manera que cada work item atraviese uno o varios planos y lo completen las personas que tengan las skills oportunas.
- Utilizar un sistema Kanban para los planos de identificación, entendimiento e ideación y luego trabajar con los diferentes equipos en scrum (por decir el framework de agilidad más usado) en el plano de implementación. A la hora de gestionar la capacidad (sobre todo en la estimación de scrum) habría que considerar que algunos miembros contribuyen en varios planos.
- Trabajar con un equipo scrum en los planos de identificación, entendimiento e ideación y luego trabajar con los diferentes equipos en scrum en el plano de implementación. En este caso, como scrum tiene una serie de ceremonias determinadas, si un integrante del scrum de un plano pertenece o participa también en otros scrums, podría existir un riesgo de ineficiencia.
Muchas gracias por el feedback y ayudar en la divulgación a Jerónimo Palacios, Marcelo Soria, Victor Adaíl y Jairo Alberto.
Los autores de este artículo somos César de Pablo Sánchez y Félix Serrano Martín. Nos conocimos trabajando en BBVA D&A, César trabajando como Científico de Datos y Félix como Agile Coach. Las opiniones expresadas por ambos en este artículo son personales y no necesariamente las de su empleador.
 César de Pablo es Ingeniero de Telecomunicaciones por la ETSIT-UPM y Doctor en Ingeniería Informática por la UC3M. Tiene más de 15 años de experiencia en desarrollo de productos y soluciones basadas en análisis de datos, aprendizaje automático y procesamiento de lenguaje natural.
César de Pablo es Ingeniero de Telecomunicaciones por la ETSIT-UPM y Doctor en Ingeniería Informática por la UC3M. Tiene más de 15 años de experiencia en desarrollo de productos y soluciones basadas en análisis de datos, aprendizaje automático y procesamiento de lenguaje natural.